Customization Guide¶
This document covers the customization of WeeWX. It assumes that you have read, and are reasonably familiar with, the Users Guide.
The introduction contains an overview of the architecture. If you are only interested in customizing the generated reports you can probably skip the introduction and proceed directly to the section Customizing reports. With this approach you can easily add new plot images, change the titles of images, change the units used in the reports, and so on.
However, if your goal is a specialized application, such as adding alarms, RSS feeds, etc., then it would be worth your while to read about the internal architecture.
Most of the guide applies to any hardware, but the exact data types are hardware-specific. See the WeeWX Hardware Guide for details of how different observation types are handled by different types hardware.
Warning
WeeWX is still an experimental system and, as such, its internal design is subject to change. Future upgrades may break any customizations you have done, particularly if they involve the API (skin customizations tend to be more stable).
Overall system architecture¶
Below is a brief overview of the WeeWX system architecture, which is covered in much more detail in the rest of this document.
-
A WeeWX process normally handles the monitoring of one station — e.g. a weather station. The process is configured using options in a configuration file, typically called
weewx.conf. -
A WeeWX process has at most one "driver" to communicate with the station hardware and receive "high resolution" (i.e. every few seconds) measurement data in the form of LOOP packets. The driver is single-threaded and blocking, so no more than one driver can run in a WeeWX process.
-
LOOP packets may contain arbitrary data from the station/driver in the form of a Python dictionary. Each LOOP packet must contain a time stamp and a unit system, in addition to any number of observations, such as temperature or humidity. For extensive types, such as rain, the packet contains the total amount of rain that fell during the observation period.
-
WeeWX then compiles these LOOP packets into regularly spaced "archive records". For most types, the archive record contains the average value seen in all the LOOP packets over the archive interval (typically 5 minutes). For extensive types, such as rain, it is the sum of all values over the archive interval.
-
Internally, the WeeWX engine uses a pipeline architecture, consisting of many services. Services bind to events of interest, such as new LOOP packets, or new archive records. Events are then run down the pipeline in order — services at the top of the pipeline act on the data before services farther down the pipe.
-
Services can do things such as check the data quality, apply corrections, or save data to a database. Users can easily add new services.
-
WeeWX includes an ability to customize behavior by installing extensions. Extensions may consist of one or more drivers, services, and/or skins, all in an easy-to-install package.
Data architecture¶
WeeWX is data-driven. When the sensors spit out some data, WeeWX does something. The "something" might be to print out the data, or to generate an HTML report, or to use FTP to copy a report to a web server, or to perform some calculations using the data.
A driver is Python code that communicates with the hardware. The driver reads data from a serial port or a device on the USB or a network interface. It handles any decoding of raw bits and bytes, and puts the resulting data into LOOP packets. The drivers for some kinds of hardware (most notably, Davis Vantage) are capable of emitting archive records as well.
In addition to the primary observation types such as temperature, humidity, or solar radiation, there are also many useful dependent types, such as wind chill, heat index, or ET, which are calculated from the primary data. The firmware in some weather stations are capable of doing many of these calculations on their own. For the rest, should you choose to do so, the WeeWX service StdWXCalculate can fill in the gaps. Sometimes the firmware simply does it wrong, and you may choose to have WeeWX do the calculation, despite the type's presence in LOOP packets.
LOOP packets vs. archive records¶
Generally, there are two types of data that flow through WeeWX: LOOP packets, and archive records. Both are represented as Python dictionaries.
LOOP packets¶
LOOP packets are the raw data generated by the device driver. They get their name from the Davis Instruments documentation. For some devices they are generated at rigid intervals, such as every 2 seconds for the Davis Vantage series, for others, irregularly, every 20 or 30 seconds or so. LOOP packets may or may not contain all the data types an instrument is capable of measuring. For example, a packet may contain only temperature data, another only barometric data, etc. These kinds of packet are called partial record packets. By contrast, other types of hardware (notably the Vantage series) include every data type in every LOOP packet.
In summary, LOOP packets can be highly irregular in time and in what they contain, but they come in frequently.
Archive records¶
By contrast, archive records are highly regular. They are generated at regular intervals (typically every 5 to 30 minutes), and all contain the same data types. They represent an aggregation of the LOOP packets over the archive interval. The exact kind of aggregation depends on the data type. For example, for temperature, it's generally the average temperature over the interval. For rain, it's the sum of rain over the interval. For battery status it's the last value in the interval.
Some hardware is capable of generating their own archive records (the Davis Vantage and Oregon Scientific WMR200, for example), but for hardware that cannot, WeeWX generates them.
It is the archive data that is put in the SQL database, although, occasionally, the LOOP packets can be useful (such as for the Weather Underground's "Rapidfire" mode).
What to customize¶
For configuration changes, such as which skins to use, or enabling posts to
the Weather Underground, simply modify the WeeWX configuration file, nominally
weewx.conf. Any changes you make will be preserved during an upgrade.
Customization of reports may require changes to a skin configuration file
skin.conf or template files ending in .tmpl or .inc. Anything in the
skins subdirectory is also preserved across upgrades.
You may choose to install one of the many third-party extensions that are available for WeeWX. These are typically installed in either the skins or user subdirectories, both of which are preserved across upgrades.
More advanced customizations may require new Python code or modifications of
example code. These should be placed in the user directory, where they will
be preserved across upgrades. For example, if you wish to modify one of the
examples that comes with WeeWX, copy it from the examples directory to the
user directory, then modify it there. This way, your modifications will not
be touched if you upgrade.
For code that must run before anything else in WeeWX runs (for example, to set
up an environment), put it in the file extensions.py in the user directory.
It is always run before the WeeWX engine starts up. Because it is in the
user subdirectory, it is preserved between upgrades.
Do I need to restart WeeWX?¶
If you make a change in weewx.conf, you will need to restart weewxd.
If you modify Python code in the user directory or elsewhere, you will need
to restart weewxd.
If you install an extension, you will need to restart weewxd.
If you make a change to a template or to a skin.conf file, then you do not
need to restart weewxd. The change will be adopted at the next reporting
cycle, typically at the end of an archive interval.
Running reports on demand¶
If you make changes, how do you know what the results will look like? You
could just run weewxd and wait until the next reporting cycle kicks off but,
depending on your archive interval, that could be a 30-minute wait or more.
The utility weectl report
run allows you to run a
report whenever you like. To use it, just run it from a command line.
Optionally, you can tell it what to use as the "Current" time, using either
option --epoch, or by using the combination of --date and --time.
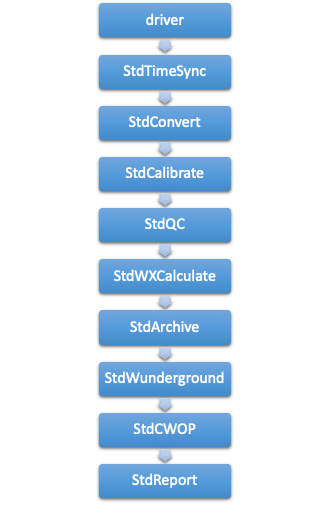
The WeeWX service architecture¶
At a high-level, WeeWX consists of an engine class called StdEngine. It is
responsible for loading services, then arranging for them to be called when
key events occur, such as the arrival of LOOP or archive data. The default
install of WeeWX includes the following services:
| Service | Function |
| weewx.engine.StdTimeSynch | Arrange to have the clock on the station synchronized at regular intervals. |
| weewx.engine.StdConvert | Converts the units of the input to a target unit system (such as US or Metric). |
| weewx.engine.StdCalibrate | Adjust new LOOP and archive packets using calibration expressions. |
| weewx.engine.StdQC | Check quality of incoming data, making sure values fall within a specified range. |
| weewx.wxservices.StdWXCalculate | Decide which derived observation types need to be calculated. |
| weewx.wxxtypes.StdWXXTypes weewx.wxxtypes.StdPressureCooker weewx.wxxtypes.StdRainRater weewx.wxxtypes.StdDelta |
Calculate derived variables, such as ET, dewpoint, or rainRate. |
| weewx.engine.StdArchive | Archive any new data to the SQL databases. |
| weewx.restx.StdStationRegistry weewx.restx.StdWunderground weewx.restx.StdPWSweather weewx.restx.StdCWOP weewx.restx.StdWOW weewx.restx.StdAWEKAS |
Various RESTful services (simple stateless client-server protocols), such as the Weather Underground, CWOP, etc. Each launches its own, independent thread, which manages the post. |
| weewx.engine.StdPrint | Print out new LOOP and archive packets on the console. |
| weewx.engine.StdReport | Launch a new thread to do report processing after a new archive record arrives. Reports do things such as generate HTML or CSV files, generate images, or transfer files using FTP/rsync. |
It is easy to extend old services or to add new ones. The source distribution includes an example new service called MyAlarm, which sends an email when an arbitrary expression evaluates True. These advanced topics are covered later in the section Customizing the WeeWX service engine.
The standard reporting service StdReport¶
For the moment, let us focus on the last service, weewx.engine.StdReport,
the standard service for creating reports. This will be what most users will
want to customize, even if it means just changing a few options.
Reports¶
The standard reporting service, StdReport, runs zero or more reports. The
specific reports which get run are set in the configuration file weewx.conf,
in section [StdReport].
The default distribution of WeeWX includes six reports:
| Report | Default functionality |
| SeasonsReport | Introduced with WeeWX V3.9, this report generates a single HTML file with day, week, month and year "to-date" summaries, as well as the plot images to go along with them. Buttons select which timescale the user wants. It also generates HTML files with more details on celestial bodies and statistics. Also generates NOAA monthly and yearly summaries. |
| SmartphoneReport | A simple report that generates an HTML file, which allows "drill down" to show more detail about observations. Suitable for smaller devices, such as smartphones. |
| MobileReport | A super simple HTML file that just shows the basics. Suitable for low-powere d or bandwidth-constrained devices. |
| StandardReport | This is an older report that has been used for many years in WeeWX. It generates day, week, month and year "to-date" summaries in HTML, as well as the plot images to go along with them. Also generates NOAA monthly and yearly summaries. It typically loads faster than the SeasonsReport. |
| FTP | Transfer everything in the HTML_ROOT directory to a remote server using ftp. |
| RSYNC | Transfer everything in the HTML_ROOT directory to a remote server using the utility rsync. |
Note that the FTP and RSYNC "reports" are a funny kind of report in that they do not actually generate anything. Instead, they use the reporting service engine to transfer files and folders to a remote server.
Skins¶
Each report has a skin associated with it. For most reports, the
relationship with the skin is an obvious one: the skin contains the templates,
any auxiliary files such as background GIFs or CSS style sheets, files with
localization data, and a skin configuration file, skin.conf. If you will,
the skin controls the look and feel of the report. Note that more than one
report can use the same skin. For example, you might want to run a report that
uses US Customary units, then run another report against the same skin, but
using metric units and put the results in a different place. All this is
possible by either overriding configuration options in the WeeWX configuration
file or the skin configuration file.
Like all reports, the FTP and RSYNC "reports" also use a skin, and include a skin configuration file, although they are quite minimal.
Skins live in their own directory called skins, whose location is referred
to as SKIN_ROOT.
Note
The symbol SKIN_ROOT is a symbolic name to the location of the
directory where your skins are located. It is not to be taken literally.
Consult the section Where to find things in the
User's Guide for its exact location, dependent on how you installed
WeeWX and what operating system you are using
Generators¶
To create their output, skins rely on one or more generators, which are what do the actual work, such as creating HTML files or plot images. Generators can also copy files around or FTP/rsync them to remote locations. The default install of WeeWX includes the following generators:
| Generator | Function |
| weewx.cheetahgenerator.CheetahGenerator | Generates files from templates, using the Cheetah template engine. Used to generate HTML and text files. |
| weewx.imagegenerator.ImageGenerator | Generates graph plots. |
| weewx.reportengine.FtpGenerator | Uploads data to a remote server using FTP. |
| weewx.reportengine.RsyncGenerator | Uploads data to a remote server using rsync. |
| weewx.reportengine.CopyGenerator | Copies files locally. |
Note that the three generators FtpGenerator, RsyncGenerator, and
CopyGenerator do not actually generate anything having to do with the
presentation layer. Instead, they just move files around.
Which generators are to be run for a given skin is specified in the skin's configuration file, in the section [Generators].
Templates¶
A template is a text file that is processed by a template engine to create
a new file. WeeWX uses the Cheetah template
engine. The generator weewx.cheetahgenerator.CheetahGenerator is responsible
for running Cheetah at appropriate times.
A template may be used to generate HTML, XML, CSV, Javascript, or any other type of text file. A template typically contains variables that are replaced when creating the new file. Templates may also contain simple programming logic.
Each template file lives in the skin directory of the skin that uses it. By
convention, a template file ends with the .tmpl extension. There are also
template files that end with the .inc extension. These templates are
included in other templates.
The database¶
WeeWX uses a single database to store and retrieve the records it needs. It can be implemented by using either SQLite, an open-source, lightweight SQL database, or MySQL, an open-source, full-featured database server.
Structure¶
Inside this database are several tables. The most important is the
archive table, a big flat table, holding one record for each archive
interval, keyed by dateTime, the time at the end of the archive interval.
It looks something like this:
| dateTime | usUnits | interval | barometer | pressure | altimeter | inTemp | outTemp | ... |
| 1413937800 | 1 | 5 | 29.938 | null | null | 71.2 | 56.0 | ... |
| 1413938100 | 1 | 5 | 29.941 | null | null | 71.2 | 55.9 | ... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
The first three columns are required. Here's what they mean:
| Name | Meaning |
| dateTime | The time at the end of the archive interval in unix epoch time. This is the primary key in the database. It must be unique, and it cannot be null. |
| usUnits | The unit system the record is in. It cannot be null. See the Units for how these systems are encoded. |
| interval | The length of the archive interval in minutes. It cannot be null. |
In addition to the archive table, there are a number of smaller tables inside
the database, one for each observation type, which hold daily summaries of
the type, such as the minimum and maximum value seen during the day, and at
what time. These tables have names such as archive_day_outTemp or
archive_day_barometer. They are there to optimize certain types of queries
— their existence is generally transparent to the user. For more details,
see the section Daily summaries in the
Developer's Notes.
Binding names¶
While most users will only need the one weather database that comes with WeeWX, the reporting engine allows you to use multiple databases in the same report. For example, if you have installed the cmon computer monitoring package , which uses its own database, you may want to include some statistics or graphs about your server in your reports, using that database.
An additional complication is that WeeWX can use more than one database implementation: SQLite or MySQL. Making users specify in the templates not only which database to use, but also which implementation, would be unreasonable.
The solution, like so many other problems in computer science, is to introduce
another level of indirection, a database binding. Rather than specify which
database to use, you specify which binding. Bindings do not change with the
database implementation, so, for example, you know that wx_binding will
always point to the weather database, no matter if its implementation is a
sqlite database or a MySQL database. Bindings are listed in section
[DataBindings] in the
WeeWX configuration file.
The standard weather database binding that WeeWX uses is wx_binding. This
is the binding that you will be using most of the time and, indeed, it is the
default. You rarely have to specify it explicitly.
Programming interface¶
WeeWX includes a module called weedb that provides a single interface for
many of the differences between database implementations such as SQLite and
MySQL. However, it is not uncommon to make direct SQL queries within services
or search list extensions. In such cases, the SQL should be generic so that
it will work with every type of database.
The database manager class provides methods to create, open, and query a database. These are the canonical forms for obtaining a database manager.
If you are opening a database from within a WeeWX service:
db_manager = self.engine.db_binder.get_manager(data_binding='name_of_binding', initialize=True)
# Sample query:
db_manager.getSql("SELECT SUM(rain) FROM %s "\\
"WHERE dateTime>? AND dateTime<=?" % db_manager.table_name, (start_ts, stop_ts))
If you are opening a database from within a WeeWX search list extension, you
will be passed in a function db_lookup() as a parameter, which can then be
used to bind to a database. By default, it returns a manager bound to
wx_binding:
wx_manager = db_lookup() # Get default binding
other_manager = db_lookup(data_binding='some_other_binding') # Get an explicit binding
# Sample queries:
wx_manager.getSql("SELECT SUM(rain) FROM %s "\\
"WHERE dateTime>? AND dateTime<=?" % wx_manager.table_name, (start_ts, stop_ts))
other_manager.getSql("SELECT SUM(power) FROM %s"\\
"WHERE dateTime>? AND dateTime<=?" % other_manager.table_name, (start_ts, stop_ts))
If opening a database from somewhere other than a service, and there is no
DBBinder available:
db_manager = weewx.manager.open_manager_with_config(config_dict, data_binding='name_of_binding')
# Sample query:
db_manager.getSql("SELECT SUM(rain) FROM %s "\\
"WHERE dateTime>? AND dateTime<=?" % db_manager.table_name, (start_ts, stop_ts))
The DBBinder caches managers, and thus database connections. It cannot be
shared between threads.
Units¶
The unit architecture in WeeWX is designed to make basic unit conversions and display of units easy. It is not designed to provide dimensional analysis, arbitrary conversions, and indications of compatibility.
The driver reads observations from an instrument and converts them, as necessary, into a standard set of units. The actual units used by each instrument vary widely; some instruments use Metric units, others use US Customary units, and many use a mixture. The driver can emit measurements in any unit system, but it must use the same unit system for all values in a LOOP packet or archive record.
By default, and to maintain compatibility with wview, the default database units are US Customary, although this can be changed.
Note that whatever unit system is used in the database, data can be displayed using any unit system. So, in practice, it does not matter what unit system is used in the database.
Each observation type, such as outTemp or pressure, is associated with a
unit group, such as group_temperature or group_pressure. Each unit group
is associated with a unit type such as degree_F or mbar. The reporting
service uses this architecture to convert observations into a target unit
system, to be displayed in your reports.
With this architecture one can easily create reports with, say, wind measured in knots, rain measured in mm, and temperatures in degree Celsius. Or one can create a single set of templates, but display data in different unit systems with only a few stanzas in a configuration file.